Материалы по тегу: isc 2022
|
30.05.2022 [10:00], Игорь Осколков
Июньский TOP500: есть экзафлопс!59-я редакция TOP500, публичного рейтинга самых производительных суперкомпьютеров мира, стала наиболее знаменательной за последние 14 лет, поскольку официально был преодолён экзафлопсный барьер. Путь от петафлопса оказался долгим — первой петафлопсной системой стал суперкомпьютер IBM Roadrunner, и произошло это аж в 2008 году. Но минимальным порогом для попадания в TOP500 эта отметка стала только в 2019 году. Как и было обещано, официально и публично отметку в 1 Эфлопс в бенчмарке HPL на FP64-вычислениях первым преодолел суперкомпьютер Frontier — его устоявшаяся производительность составила 1,102 Эфлопс при теоретическом пике в 1,686 Эфлопс. Система на платформе HPE Cray EX235a использует оптимизированные 64-ядерные процессоры AMD EPYC Milan (2 ГГц), ускорители AMD Instinct MI250X и фирменный интерконнект Slingshot 11-го поколения. Система имеет суммарно 8 730 112 ядер, потребляет 21,1 МВт и выдаёт 52,23 Гфлопс/Вт, что делает её второй по энергоэффективности в мире. 
Суперкомпьютер Frontier (Фото: AMD) Впрочем, первое место в Green500 по данному показателю всё равно занимает тестовый кластер в составе всё того же Frontier: 120 832 ядра, 19,2 Пфлопс, 309 кВт, 62,68 Гфлопс/Вт. Третье и четвёртое места достались европейским машинам LUMI и Adastra, новичкам TOP500, которые по «железу» идентичны Frontier, но значительно меньше. Да и разница в Гфлопс/Вт между ними минимальна. Скопом они сместили предыдущего лидера — экзотичную японскую систему MN-3 от Preferred Networks. Японская система Fugaku, лидер по производительности в течение двух последних лет, сместилась на второе место TOP500. Третье место у финской системы LUMI с показателем производительности 151,9 Пфлопс — обратите внимание, насколько велик разрыв в первой тройке машин. Наконец, в Топ-10 последнее место занял новичок Adastra (46,1 Пфлопс), который расположен во Франции. 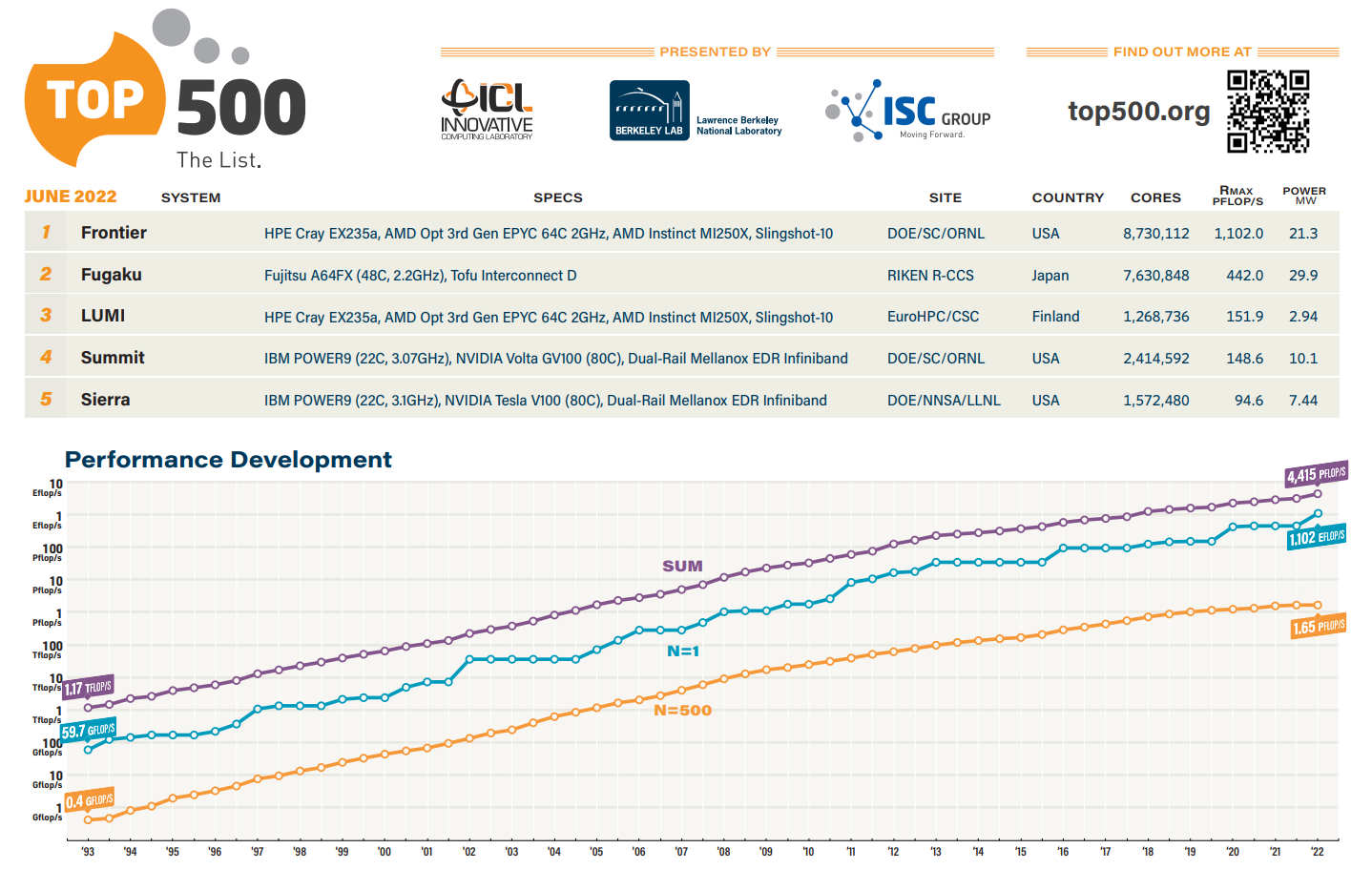
Источник: TOP500 В бенчмарке HPCG всё ещё лидирует Fugaku (16 Пфлопс), но, судя по всему, только потому, что для Frontier данных пока нет. Ну и потому, что результат суперкомпьютера LUMI, который почти на порядок медленнее Frontier, в HPCG составляет 1,94 Пфлопс. Наконец, в HPL-AI Frontier также отобрал первенство у Fugaku — 6,86 Эфлопс в вычислениях смешанной точности против 2 Эфлопс. В общем, у Frontier полная победа по всем фронтам, и эту машину можно назвать не только самой быстрой в мире, но первой по-настоящему экзафлопсной системой. Если, конечно, не учитывать неофициальные результаты OceanLight и Tianhe-3 из Поднебесной, которые в TOP500 никто не заявил. Число китайских систем в нынешнем рейтинге осталось прежним (173 шт.), тогда как США «ужались» со 150 до 127 шт. Российских систем в списке всё так же семь. Лидерами по числу поставленных систем остаются Lenovo, HPE и Inspur, а по их суммарной производительности — HPE, Fujitsu и Lenovo. С другой стороны, массовых изменений и не было — в нынешнем списке всего около сорока новых систем. 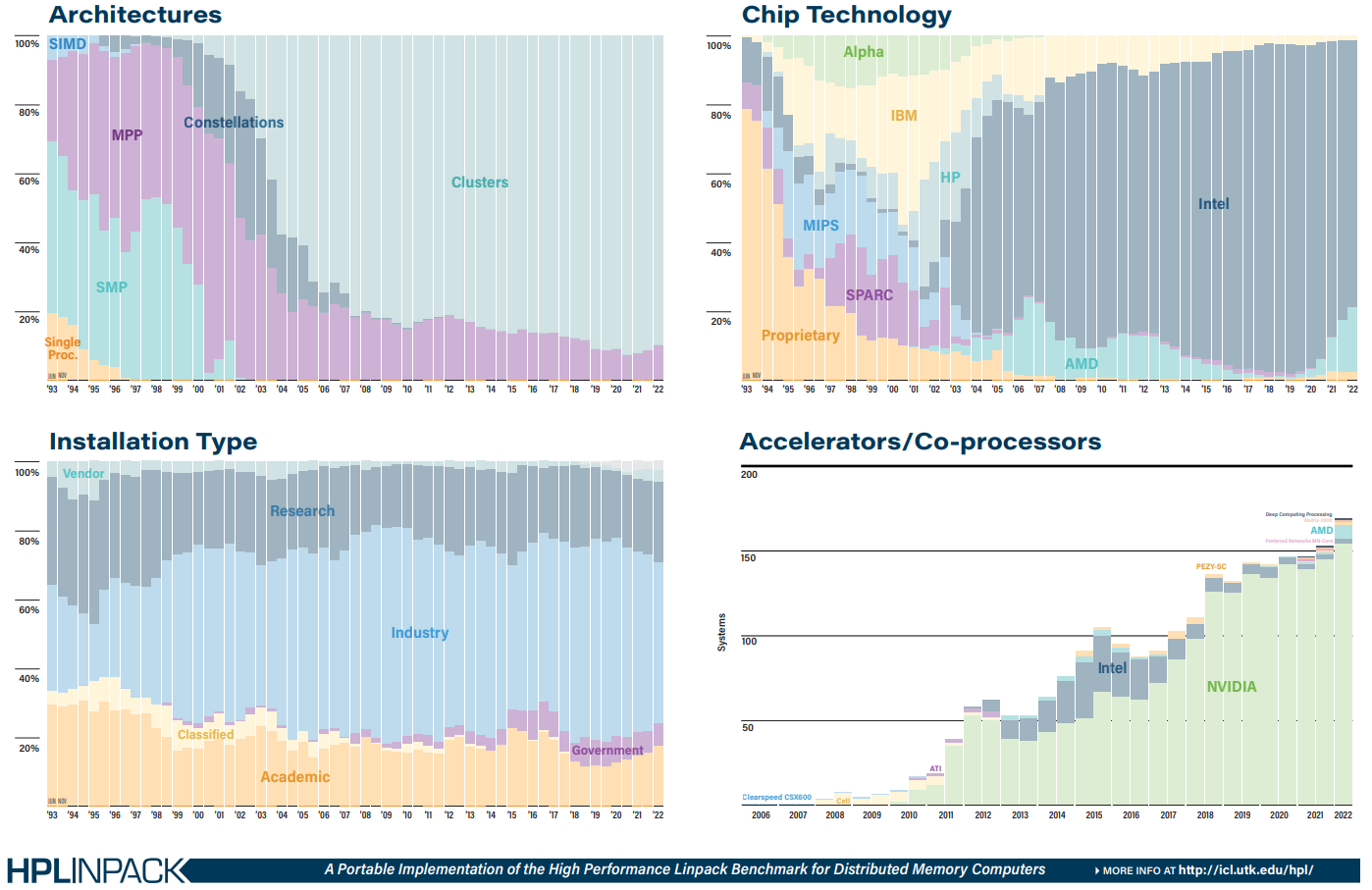
Источник: TOP500 Однако нельзя не отметить явный прогресс AMD — да, чуть больше трёх четвертей машин из списка используют процессоры Intel, но AMD удалось за полгода отъесть около 4 %. При этом AMD EPYC Milan присутствует в более чем трёх десятках систем, а доля Intel Xeon Ice Lake-SP вдвое меньше, хотя эти процессоры появились практически одновременно. Ускорители ожидаемо стали использовать больше — они применяются в 170 системах (было 150). Подавляющее большинство приходится на решения NVIDIA разных поколений, но и для новых Instinct MI250X нашлось место в восьми машинах. Ну а в области интерконнекта Infiniband потихоньку догоняет Ethernet: 226 машин против 196 + ещё 40 с Omni-Path + редкие проприетарные решения. |
|

